")
ETRI از مدل هوش بصری مولد فوق سریع_2 رونمایی کرد. اعتبار: پژوهشکده الکترونیک و مخابرات (ETRI)
محققان ETRI از فناوریای رونمایی کردهاند که هوش مصنوعی مولد و هوش بصری را برای ایجاد تصاویر از ورودیهای متن تنها در ۲ ثانیه ترکیب میکند و زمینه هوش بصری مولد فوقالعاده سریع را پیش میبرد.
پژوهشکده الکترونیک و مخابرات (ETRI) از عرضه پنج نوع مدل برای عموم خبر داد. اینها شامل سه مدل «KOALA» است که تصاویر را از ورودیهای متنی پنج برابر سریعتر از روشهای موجود تولید میکند، و دو مدل گفتاری به زبان دیداری «Ko-LLaVA» که میتواند پاسخگویی به سؤال را با تصاویر یا ویدیوها انجام دهد.
مدل 'KOALA' به طور قابل توجهی پارامترها را از 2.56B (2.56 میلیارد) مدل SW عمومی به 700M (700 میلیون) با استفاده از تکنیک تقطیر دانش کاهش داد. تعداد زیاد پارامترها معمولاً به معنای محاسبات بیشتر است که منجر به زمان پردازش طولانیتر و افزایش هزینههای عملیاتی میشود. محققان اندازه مدل را یک سوم کاهش دادند و تولید تصاویر با وضوح بالا را بهبود بخشیدند تا دو برابر سریعتر از قبل و پنج برابر سریعتر از DALL-E 3 باشد.
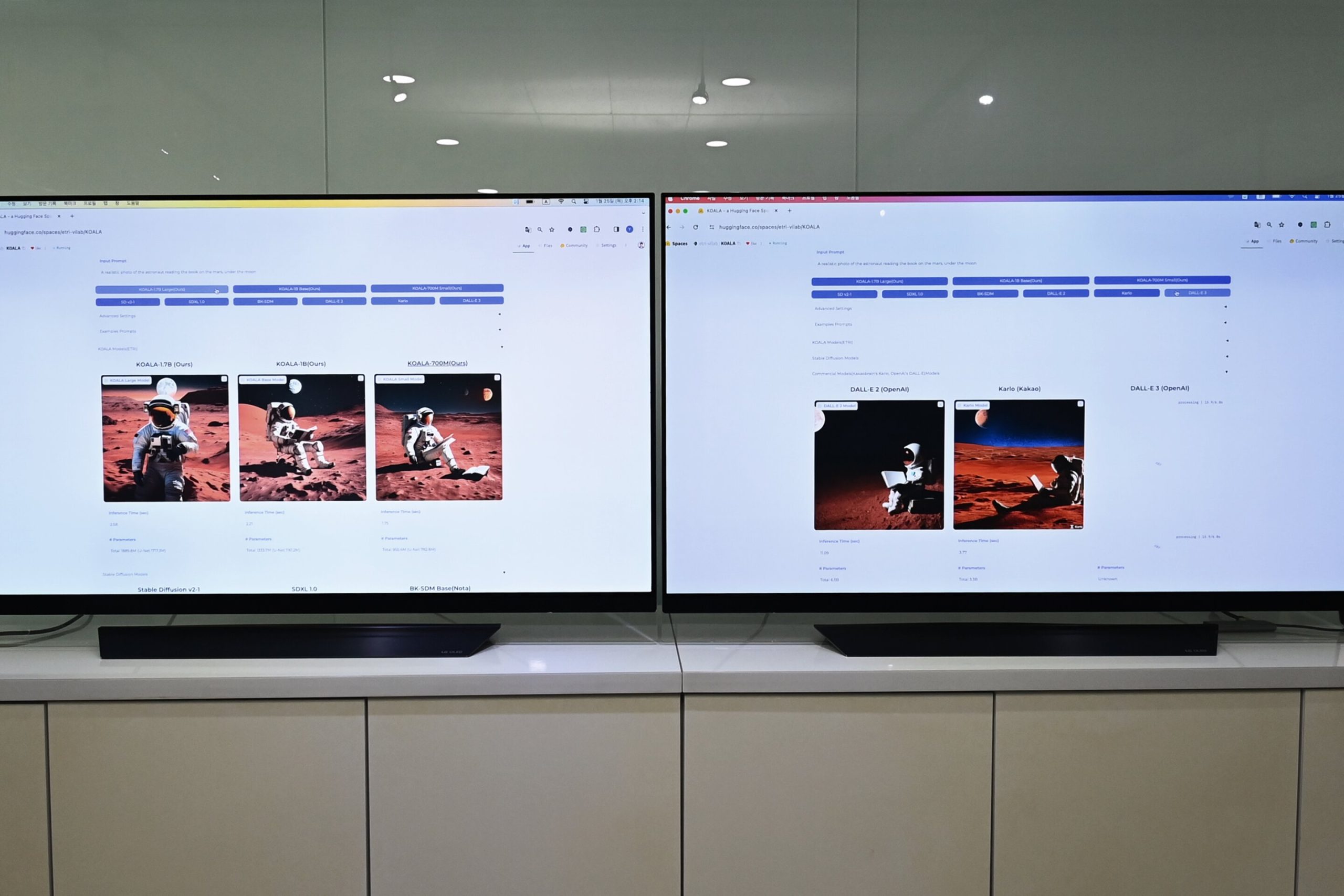
ETRI توانسته است اندازه مدل (1.7B (بزرگ)، 1B (پایه)، 700M (کوچک)) را به میزان قابل توجهی کاهش دهد و سرعت تولید را به حدود 2 ثانیه افزایش دهد و عملکرد آن را بر روی پردازندههای گرافیکی ارزانقیمت با تنها 8 گیگابایت حافظه در میان امکانپذیر سازد. چشم انداز رقابتی تولید متن به تصویر چه در داخل و چه در سطح بین المللی.
سه مدل 'KOALA' ETRI که در داخل توسعه یافته اند، در محیط HuggingFace منتشر شده اند.
در عمل، زمانی که تیم تحقیقاتی جمله «تصویری از یک فضانورد در حال خواندن کتاب زیر ماه در مریخ» را وارد کرد، مدل KOALA 700M که توسط ETRI توسعه داده شده است، تصویر را تنها در 1.6 ثانیه ایجاد کرد که به طور قابل توجهی سریعتر از Kakao Brain (3.8 ثانیه) است. ، DALL-E 2 OpenAI (12.3 ثانیه) و DALL-E 3 (13.7 ثانیه).
ETRI همچنین وبسایتی راهاندازی کرد که در آن کاربران میتوانند مستقیماً 9 مدل را مقایسه و تجربه کنند، از جمله دو مدل انتشار پایدار در دسترس عموم، BK-SDM، Karlo، DALL-E 2، DALL-E 3، و سه مدل KOALA.
علاوه بر این، تیم تحقیقاتی از مدل زبان بصری محاوره ای «Ko-LLaVA» رونمایی کرد که هوش بصری را به هوش مصنوعی مکالمه مانند ChatGPT اضافه می کند. این مدل میتواند تصاویر یا ویدیوها را بازیابی کند و به زبان کرهای در مورد آنها پاسخگویی را انجام دهد.
مدل 'LLaVA' در یک پروژه تحقیقاتی مشترک بینالمللی با دانشگاه ویسکانسین-مدیسون و ETRI که در کنفرانس معتبر هوش مصنوعی NeurIPS'23 ارائه شد، توسعه یافت و از LLaVA (دستیار زبان و بینایی بزرگ) منبع باز با تفسیر تصویر استفاده میکند. قابلیت ها در سطح GPT-4.
محققان در حال انجام تحقیقات توسعه ای برای بهبود درک زبان کره ای و معرفی قابلیت های تفسیر ویدیویی بی سابقه بر اساس مدل LLaVA هستند که به عنوان جایگزینی برای مدل های چندوجهی از جمله تصاویر در حال ظهور است.
علاوه بر این، ETRI از قبل مدل نسل درک زبان فشرده مبتنی بر کره خود (KEByT5) را منتشر کرد. مدلهای منتشر شده (330M (کوچک)، 580M (پایه)، 1.23B (بزرگ)) از فناوری بدون رمز استفاده میکنند که قادر به رسیدگی به نئولوژیسمها و کلمات آموزشدیده نیست. سرعت تمرین بیش از 2.7 برابر و سرعت استنتاج بیش از 1.4 برابر افزایش یافت.
تیم تحقیقاتی تغییر تدریجی در بازار هوش مصنوعی مولد از مدلهای تولیدی متن محور به مدلهای مولد چندوجهی را پیشبینی میکند، با گرایشی در حال ظهور به سمت مدلهای کوچکتر و کارآمدتر در چشمانداز رقابتی اندازههای مدل.
دلیل اینکه ETRI این مدل را عمومی می کند، تقویت یک اکوسیستم در بازار مرتبط با کاهش اندازه مدل است که به طور سنتی به هزاران سرور نیاز دارد و در نتیجه استفاده در شرکت های کوچک و متوسط را تسهیل می کند.
در آینده، تیم تحقیقاتی انتظار دارد تقاضای زیادی برای مدلهای متقابل کرهای که فناوری هوش بصری را در مدلهای زبان باز برجسته هوش مصنوعی ادغام میکنند، بالا باشد.
این تیم تاکید کرد که امتیاز اصلی این فناوری مبتنی بر تقطیر دانش است، فناوری که مدلهای کوچک را قادر میسازد تا با انباشت دانش با استفاده از هوش مصنوعی، نقش مدلهای بزرگ را انجام دهند.
پس از عمومی کردن این فناوری، ETRI قصد دارد آن را به خدمات تولید تصویر، خدمات آموزشی خلاقانه، تولید محتوا و کسبوکارها انتقال دهد.
لی یونگ جو، مدیر بخش تحقیقات هوش بصری ETRI، اظهار داشت: “از طریق تلاش های مختلف در زمینه فناوری هوش مصنوعی مولد، ما قصد داریم طیف وسیعی از مدل هایی را منتشر کنیم که اندازه کوچکی دارند اما از نظر عملکرد عالی هستند. هدف تحقیقات جهانی ما شکستن این وابستگی است. بر روی مدلهای بزرگ موجود و به شرکتهای کوچک و متوسط داخلی فرصتی برای استفاده مؤثر از فناوری هوش مصنوعی ارائه میکند.”
پروفسور لی یونگ جائه از دانشگاه ویسکانسین مدیسون که بر پروژه LLaVA نظارت می کند، گفت: “در رهبری پروژه LLaVA، ما تحقیقاتی را بر روی مدل های زبان بصری مبتنی بر منبع باز انجام دادیم تا برای افراد بیشتری قابل رقابت باشد. در مقابل GPT-4. ما قصد داریم تحقیقات خود را در مورد مدل های مولد چندوجهی از طریق تحقیقات مشترک بین المللی با ETRI ادامه دهیم.”
هدف تیم تحقیقاتی نشان دادن قابلیتهای تحقیقاتی در سطح جهانی، فراتر از انواع معمولی هوش مصنوعی مولد است که ورودیهای متن را به پاسخهای متنی تبدیل میکند. آنها قصد دارند تحقیقات خود را به انواعی که با جملات به تصاویر یا فیلم ها پاسخ می دهند و انواعی که با تصاویر یا فیلم ها به جملات پاسخ می دهند گسترش دهند.
ارائه شده توسط شورای ملی تحقیقات علم و فناوری
نقل قول: مدل هوش بصری مولد فوق سریع تصاویر را تنها در 2 ثانیه ایجاد می کند (2024، 22 فوریه) بازیابی شده در 23 فوریه 2024 از https://techxplore.com/news/2024-02-ultra-fast-generative-visual-intelligence.html
این برگه یا سند یا نوشته تحت پوشش قانون کپی رایت است. به غیر از هرگونه معامله منصفانه به منظور مطالعه یا تحقیق خصوصی، هیچ بخشی بدون اجازه کتبی قابل تکثیر نیست. محتوای مذکور فقط به هدف اطلاع رسانی ایجاد شده است.